В феврале этого года Anthropic официально обвинила
DeepSeek
в краже данных. Тысячи фейковых аккаунтов, миллионы украденных диалогов с Claude - и всё это, судя по всему, пошло в обучение следующей модели. Той самой, которая выходит в конце апреля.
Я слежу за
DeepSeek
с того момента, когда R1 обвалил акции Nvidia в январе 2025. С тех пор использую его почти каждый день - для работы с текстами, для кода, иногда просто чтобы быстро разобраться в теме. И когда 7 апреля утёк скриншот нового интерфейса с тремя режимами, которых раньше не было, стало понятно: это не очередное обновление. Это другое поколение.
Объясняю что происходит - без технического мусора и пресс-релизного тона.
Кто такой DeepSeek и почему нам важно следить
Быстро, для тех кто не в теме - один абзац и двигаемся дальше.
DeepSeek
- китайский стартап из Ханчжоу, основанный в 2023 году хедж-фондом High-Flyer. В январе 2025 они выпустили R1 - модель уровня GPT-4, обученную за
6 миллионов долларов
. OpenAI потратила на GPT-4 около ста миллионов. Это не опечатка и не маркетинговое преувеличение - это подтверждённые данные.
Для пользователей из России два конкретных плюса: работает без VPN и бесплатен для большинства задач. Пока ChatGPT требует подписку и периодически блокируется, DeepSeek просто работает. Причём работает на русском нормально - не идеально, но значительно лучше чем год назад.
Сейчас актуальны три версии: V3.2 - основная, R1 - режим глубокого мышления, и ожидаемый V4. Подробнее о том, чем они различаются и какую выбрать под задачу, в нашем
разборе моделей DeepSeek
Скандал с Anthropic: украли данные у Claude?
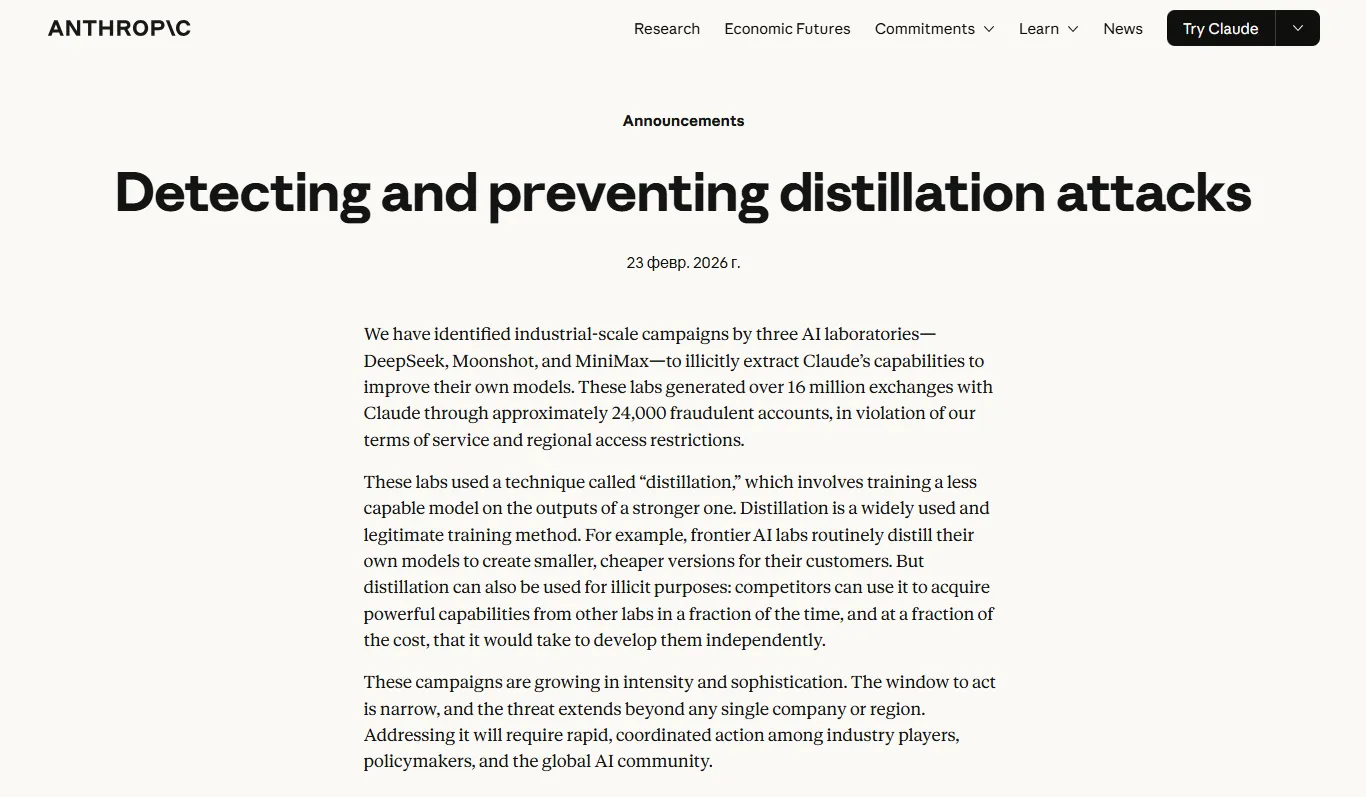
В феврале 2026 Anthropic официально заявила: DeepSeek использовал тысячи фальшивых аккаунтов, чтобы сгенерировать миллионы диалогов с Claude и использовать их как обучающие данные. Ни DeepSeek, ни Huawei ничего не прокомментировали. Ни да, ни нет.
Что это значит на практике, если обвинение правдиво? Значит, V4 частично обучен на поведении Claude - на том, как он рассуждает, отказывается от вредных запросов, структурирует ответы. Это объясняет кое-что, что я замечал в последние полгода: DeepSeek стал заметно точнее в рассуждениях и реже галлюцинировать на фактах. Я специально гонял одни и те же запросы в обеих моделях - разрыв по качеству сократился примерно вдвое.
Это официальное обвинение, не доказанный факт. Исходит от Anthropic, задокументировано - не жёлтая пресса.
Вся история с тем, что умеет Claude сейчас и где он выигрывает у DeepSeek, - в нашем
разборе модели Claude
Мы выявили масштабные кампании, проводимые тремя лабораториями искусственного интеллекта — DeepSeek, Moonshot и MiniMax — с целью незаконного извлечения возможностей Клода для улучшения собственных моделей. Эти лаборатории совершили более 16 миллионов транзакций с Клодом через примерно 24 000 мошеннических аккаунтов, нарушая наши условия обслуживания и региональные ограничения доступа.
Источник:
Anthropic, 23 февраля 2026
Три новых режима: Fast, Expert, Vision
7 апреля китайский блогер @Yigongchang поделился в Weibo скриншотом тестового интерфейса DeepSeek. Вместо привычных двух кнопок - «Глубокое мышление» и «Умный поиск» - три новых режима.
Fast
- это V4 Lite, облегчённая версия. Быстрые ответы без длинного цикла рассуждений. Для большинства обычных задач: объяснить, переписать, придумать идею. По сути, то что сейчас делает V3.2, только быстрее.
Expert
- полноценный V4. Сложные рассуждения, программирование, аналитика. Ближайший аналог - нынешний R1, но значительно мощнее по параметрам и контексту.
Vision
- вот это интереснее всего. Поддержка изображений, документов, и судя по утечкам - видео. Прошлые версии DeepSeek с картинками справлялись плохо. Я проверял: кидал один и тот же скриншот интерфейса в DeepSeek и в GPT-4o - разница была очевидной. GPT понимал контекст изображения точнее и детальнее. Команда DeepSeek потратила последние полгода именно на это направление.
По сути, вместо одной модели выходит три. Примерно как разные режимы в фотоаппарате: авто, приоритет диафрагмы, ручной. Вместо универсального инструмента - выбор под задачу.
Триллион параметров - что это вообще такое
Здесь надо притормозить, потому что цифра звучит пугающе, но пугает зря.
1 триллион параметров
- это общий размер модели. Но DeepSeek использует архитектуру MoE (mixture of experts, смесь экспертов). Внутри модели живут сотни «специалистов», каждый заточен под свои типы задач. При каждом запросе активируется только часть - в V4 это около 32-37 миллиардов параметров.
Сравните с V3: там активных параметров примерно столько же. То есть V4 не станет медленнее. Просто экспертов внутри стало значительно больше, и модель точнее выбирает нужного под конкретный запрос.
Что реально изменится - это контекстное окно.
1 миллион токенов
против нынешних 128 тысяч. В тексте это примерно четыре «Войны и мира» целиком. Модель сможет прочитать весь ваш проект, весь код репозитория, длинную переписку - и не запутаться в деталях из начала.
Я сталкивался с этим ограничением в V3.2 постоянно. Кидаешь большой документ - и на 70-80 тысячах токенов она уже начинает «забывать» детали из первых страниц. V4 обещает решить это через технологию Engram Conditional Memory - что-то вроде избирательной долгосрочной памяти. Не хранит всё подряд, а запоминает важное. 97% точность в тестах на поиск информации в длинном контексте - если это не маркетинг, это серьёзно.
Без Nvidia: вся ставка на чипы Huawei
Эта деталь важнее чем кажется.
По данным The Information, DeepSeek V4 будет полностью построен на чипах Huawei Ascend 950PR - без единого GPU от Nvidia. Alibaba, ByteDance и Tencent уже закупили эти чипы оптом. Ожидается, что V4 задействует сотни тысяч таких ускорителей.
Причина понятна: американские экспортные ограничения отрезали Китай от H100 и A100. Вместо того чтобы остановиться, DeepSeek больше года работал с Huawei и Cambricon, переписывая ключевые компоненты кода под китайское железо.
Если V4 покажет конкурентный результат на этом оборудовании - это важнее любых бенчмарков. Означает, что технологические санкции против китайского ИИ фактически не сработали. Такого исхода явно не ожидали в Вашингтоне.
Для пользователей из России практический вывод один: DeepSeek не зависит от американских цепочек поставок. Сервис структурно устойчивее, чем кажется снаружи.
Что делать прямо сейчас
До конца апреля - две или три недели. V4 ещё не вышел.
Но текущие версии уже сильные. Как я использую их прямо сейчас:
V3.2
- для текстов, переписки, анализа документов, объяснений на русском. Быстро и достаточно точно.
- когда важно пошаговое рассуждение: математика, сложный код, задачи где нужна логика. Медленнее, но надёжнее.
Попробовать можно на
- регистрация через почту, без VPN, бесплатно.
Один нюанс: с оплатой API через российские карты это квест. Для обычного чата через браузер или приложение - никаких проблем.
Если хотите обсудить V4 или поделиться своим опытом с текущими версиями - заходите в
сообщество
Взорвёт ли V4 рынок снова
R1 в январе 2025 был настоящим шоком - акции Nvidia упали на 17% за один торговый день. Инвесторы не ожидали, что китайская компания сделает конкурентную модель в разы дешевле. Это называли «Sputnik moment» для американского ИИ.
V4 тихо не выйдет. Мультимодальность, триллион параметров, миллион токенов контекста, открытый код под Apache 2.0 - и потенциально всё это на железе, которое не попадает под санкции. Если бенчмарки при релизе окажутся сопоставимы с GPT-5.x или Claude 4, реакция рынка будет предсказуемой.
Одно, что настораживает: это уже третья задержка. Ждали в конце января, потом в феврале, потом в марте. Каждый раз выходило что-то промежуточное - V3.2, потом V4 Lite 9 марта. Утёкший скриншот с тремя режимами выглядит как последний сигнал перед запуском - такое обычно не сливают случайно.
Но даже если снова перенесут - V3.2 уже сильнее, чем всё что было год назад. DeepSeek никуда не денется. А следить за тем, что будет в конце апреля - стоит.