— новый флагман, который обходит Claude Opus 4.7 и Gemini 3.1 Pro на большинстве публичных бенчмарков и заодно удваивает цену API. Презентовали модель Грег Брокман, Миа Глэзе и Марк Чен, позиционируя её как «самую умную и интуитивную» модель компании и «шаг к супер-приложению».
Бенчмарки: где именно обошли конкурентов
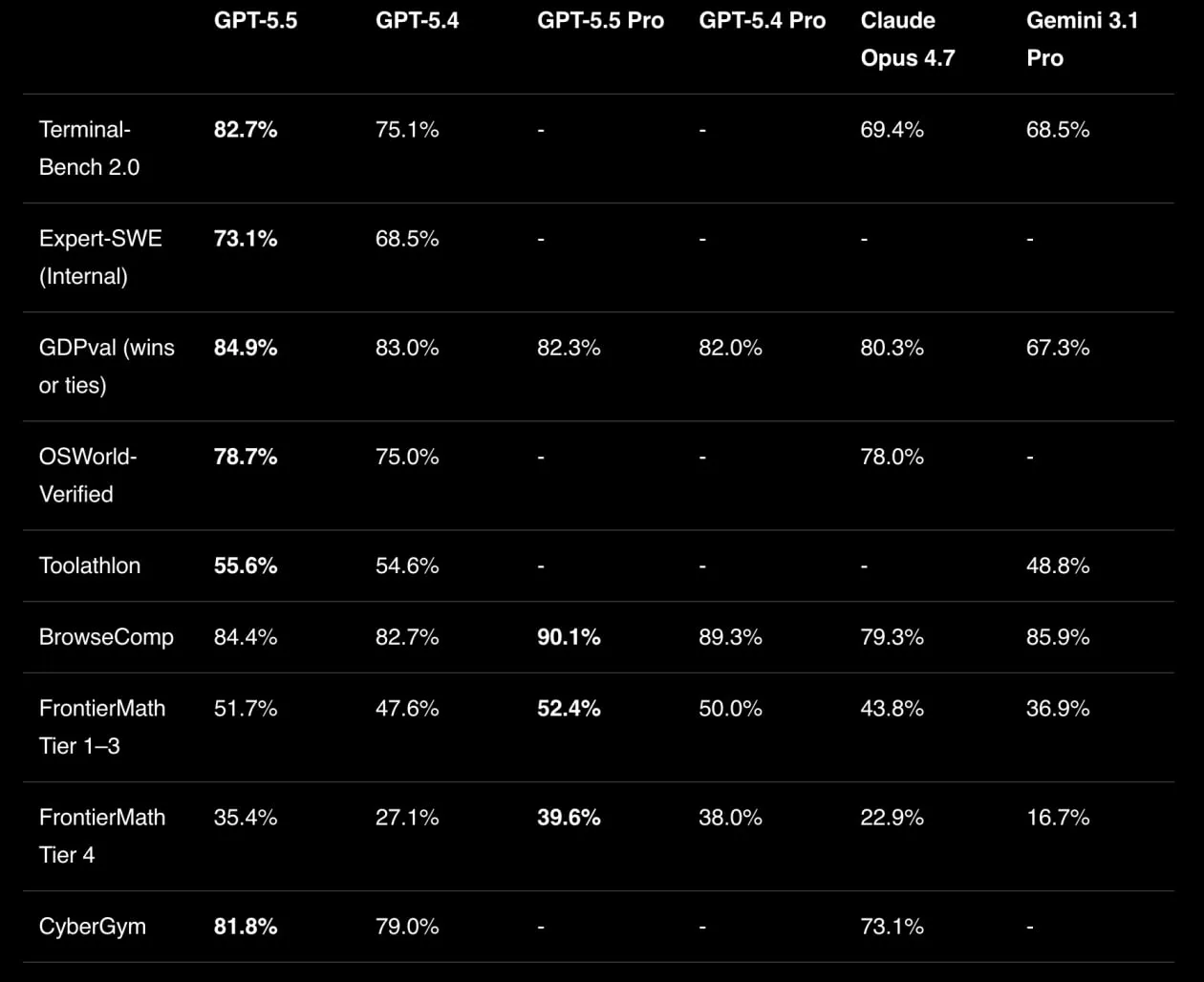
Terminal-Bench 2.0
(командная строка, агентские workflow):
82,7%
против 69,4% у Claude Opus 4.7 и 68,5% у Gemini 3.1 Pro. Предшественник GPT-5.4 выдавал 75,1%.
GDPval
(реальная работа по 44 профессиям):
84,9%
— выше уровня отраслевых профессионалов.
OSWorld-Verified
(управление ОС):
78,7%
против 78,0% у Opus 4.7.
FrontierMath Tier 1–3
51,7%
против 43,8% у Opus 4.7. GPT-5.5 Pro выдаёт
52,4%
BrowseComp
(веб-исследования, Pro-версия):
90,1%
против 85,9% у Gemini 3.1 Pro.
Tau2-bench Telecom
(клиентские сценарии):
98,0%
без prompt-тюнинга.
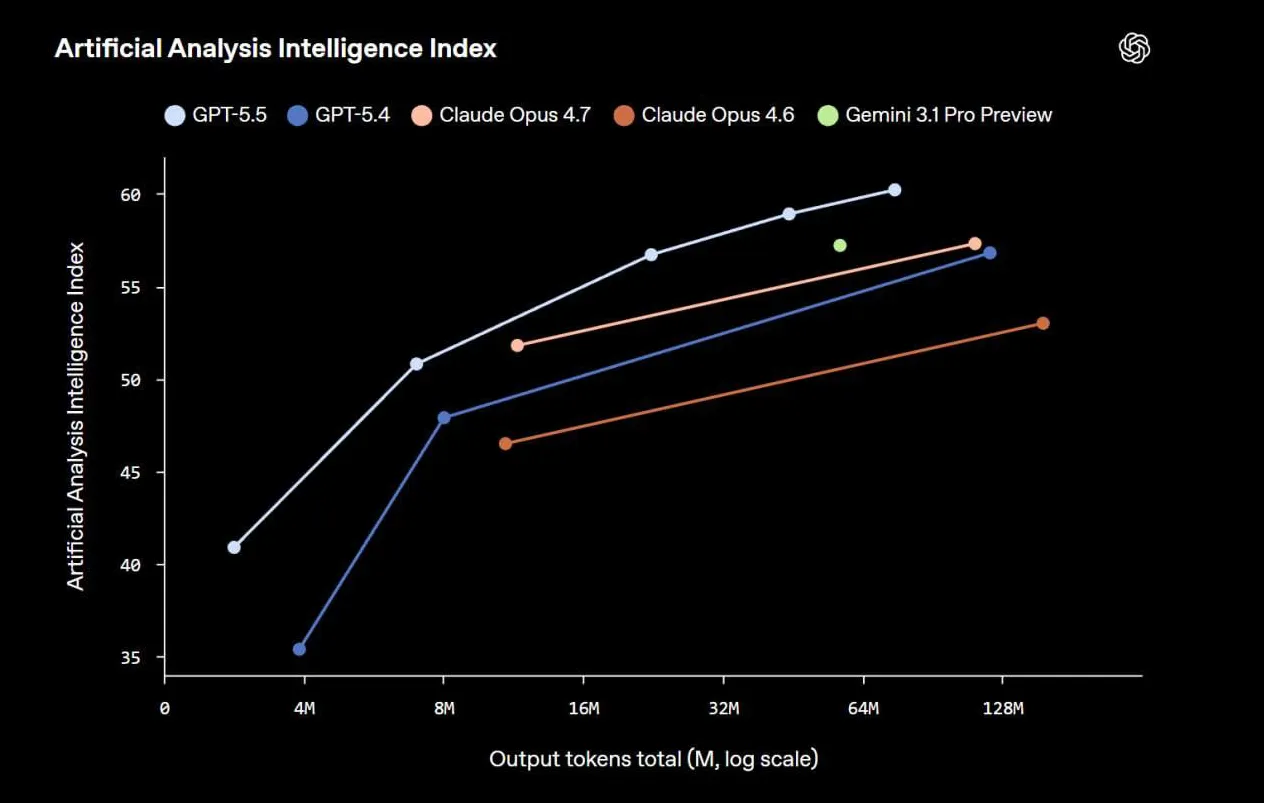
Artificial Analysis Intelligence Index
60 баллов
, +3 к Opus 4.7 и Gemini 3.1 Pro Preview.
SWE-Bench Pro
: 58,6% — тут GPT-5.5 уступает Opus 4.7 (64,3%), но OpenAI намекает, что у Anthropic «обнаружены признаки запоминания» части задач.
По данным VentureBeat, суммарно GPT-5.5 держит state-of-the-art на
14 бенчмарках
против 4 у Opus 4.7 и 2 у Gemini 3.1 Pro.
Скорость и токены
Главная инженерная фишка:
та же латентность per-token, что у GPT-5.4
, при заметно более высоком интеллекте. Для долгих Codex-задач модель тратит на ~40% меньше output-токенов. В «Expert-SWE» — внутреннем бенче на задачи, которые у человека занимают до 20 часов, — GPT-5.5 обходит 5.4 и при этом короче отвечает.
Цена: вдвое дороже
API:
$5 за миллион input-токенов и $30 за миллион output-токенов
— ровно вдвое дороже GPT-5.4 ($2,50/$15). GPT-5.5 Pro остался по цене 5.4 Pro. Контекст — 1 млн токенов. Сэм Альтман в X утверждает, что экономия на токенах частично нивелирует рост тарифа — итоговый рост расходов на типовые задачи около 20%.
Доступ
Модель уже раскатана для
Plus, Pro, Business и Enterprise
в ChatGPT и Codex. API обещают «очень скоро» — после завершения проверок безопасности. В OpenAI cybersecurity-способности GPT-5.5 классифицировали как «High», но без достижения «Critical» по preparedness framework.
Почему это важно
OpenAI отбил лидерство ровно через неделю после выхода Claude Opus 4.7 от Anthropic. Частота релизов растёт: 5.4 вышел 6–7 недель назад, 5.3 — за два дня до 5.4. Рынок frontier-моделей теперь меряется неделями, а не кварталами.