— экспериментальную открытую модель, которая генерирует текст не слово за словом, а целым блоком из 256 токенов сразу, «проявляя» его из случайного шума — так же, как нейросети-художники проявляют картинку. Итог: до
4× быстрее
на видеокарте, но качество ниже обычной Gemma 4. Веса уже лежат на Hugging Face под свободной лицензией Apache 2.0. Запустить можно локально, если есть видеокарта с ~18 ГБ памяти.
Я слежу за релизами нейросетей каждый день, и большинство из них — это «плюс полпроцента на бенчмарке». DiffusionGemma — другой случай. Это не «ещё одна модель», а другой
способ
генерировать текст. Поэтому решил разобрать сразу, пока в рунете про неё почти ничего нет: что это, чем реально полезно, какие цифры и можно ли пощупать самому.
Что такое DiffusionGemma простыми словами
Почти все привычные нейросети (ChatGPT, обычная Gemma, дипсик) пишут текст как печатная машинка — один токен за другим, слева направо, каждое следующее слово опирается на предыдущее.
DiffusionGemma работает иначе. Она начинает с «холста» из случайных токенов-заглушек и за несколько проходов уточняет их, фиксируя верные токены и используя их как подсказки для остальных, пока не получится читаемый текст. Идея украдена у генераторов картинок: там нейросеть превращает визуальный шум в чёткое изображение — здесь то же самое, но с текстом.
💡
Почему это вообще быстрее.
При обычном подходе на локальной видеокарте процессор большую часть времени простаивает, ожидая следующего «нажатия клавиши». DiffusionGemma же рисует целый абзац из 256 токенов за один проход — и загружает железо на полную. Google сравнивает это так: вместо одной печатной машинки вы получаете печатный пресс, который штампует весь блок текста разом.
Характеристики и требования
Параметр
Значение
Тип
диффузионная (text diffusion), MoE
Всего параметров
26 млрд
Активны на шаг
3,8 млрд
Генерация за проход
блок 256 токенов параллельно
Память (в квантованном виде)
~18 ГБ VRAM
Лицензия
Apache 2.0 (открытая, можно в коммерции)
Основа
семейство Gemma 4 + исследование Gemini Diffusion
Где лежат веса
Hugging Face (
Благодаря MoE-архитектуре из 26 млрд параметров на каждом шаге работают только 3,8 млрд — поэтому в квантованном виде модель помещается в 18 ГБ видеопамяти топовых потребительских видеокарт.
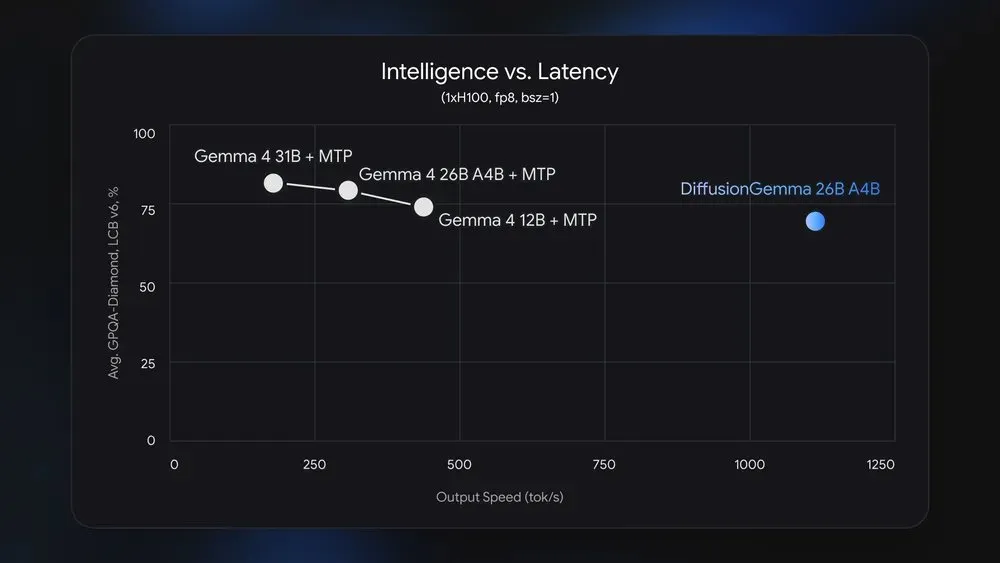
Скорость: сравнение с обычной Gemma 4
Главная цифра релиза — скорость. Вот честное сравнение диффузионной модели с её же «классическим» ровесником Gemma 4 26B (данные из бенчмарков Google и Nvidia):
Что меряем
DiffusionGemma 26B
Gemma 4 26B (обычная)
Подход
диффузия, блок сразу
токен за токеном
Скорость на H100
~1107 ток/сек
~303 ток/сек
Во сколько быстрее
~3,5–4×
базовая
Качество (тесты MMLU Pro, GPQA, AIME, код)
ниже
выше
Сильна в
вставка текста, инфиллинг кода, нелинейные задачи
общее качество, продакшн
А вот скорость на разном железе — чтобы понять, на чём её реально гонять:
Железо
Скорость генерации
NVIDIA H100 (сервер)
~1000 ток/сек
NVIDIA RTX 5090 (домашняя)
700+ ток/сек
NVIDIA DGX Station
до 800 ток/сек
NVIDIA DGX Spark (мини-ПК)
~150 ток/сек
⚠️
Без приукрашивания.
Google прямо признаёт: ради скорости качество принесено в жертву — общий уровень ответов ниже стандартной Gemma 4, и для задач, где важно максимальное качество, компания рекомендует обычную Gemma 4. Это инструмент для энтузиастов и разработчиков, а не замена ChatGPT для повседневных вопросов.
Зачем она нужна: реальные сценарии
Главная фишка — модель видит весь блок целиком, а не только то, что слева. Каждый токен «смотрит» на все остальные, включая те, что идут после него (двунаправленное внимание). Классические модели так не умеют. Отсюда сильные стороны:
Вставка текста в середину
готового абзаца — без переписывания всего.
Заполнение пропусков в коде
(code infilling) — когда нужно дописать кусок внутри функции.
Google показывает пример: после дообучения через Unslothмодель решает судоку — задачу, с которой обычные модели мучаются, потому что каждая клетка зависит от будущих.
Как запустить DiffusionGemma
Сразу честно: это не «открыл сайт и пользуешься». Нужна видеокарта или облако. Вот три реальных пути:
1. Локально на своей видеокарте.
Нужна NVIDIA с ~18+ ГБ VRAM (RTX 4090/5090 — Nvidia уже сделала под них квантованные версии). Веса берёте с Hugging Face, запускаете через один из инструментов:
🖥️
Для владельцев Mac:
на Apple Silicon модель тоже пойдёт через MLX, но прироста в 4 раза не ждите. Из-за архитектуры с общей памятью Mac упирается в пропускную способность памяти, и разрыв с обычными моделями будет меньше.
2. Через облако.
Модель доступна в Gemini Enterprise Agent Platform Model Garden и через NVIDIA NIM — если своей мощной видеокарты нет.
3. Дообучить под себя.
Для файнтюна Google выпустила JAX-инструмент Hackable Diffusion, плюс поддержка есть в Unsloth и NVIDIA NeMo.
Точные команды и код — в
официальном гайде разработчика DiffusionGemma
. Из РФ для скачивания весов с Hugging Face может понадобиться VPN.
Это вообще новое?
И да, и нет. Сама идея диффузии для текста в исследованиях не нова, но применить её к большим моделям долго не удавалось. Раньше Google показывала демо Gemini Diffusion, а стартап Inception в начале 2026 года выпустил Mercury 2 — первую, по их словам, диффузионную модель с рассуждениями. Но DiffusionGemma — первая такая модель
с открытыми весами от Google
, которую может скачать каждый. В этом её ценность.
Частые вопросы (FAQ)
Что такое DiffusionGemma простыми словами?
Это открытая нейросеть Google, которая генерирует текст методом диффузии — не слово за словом, а целым блоком из 256 токенов, «проявляя» его из случайного шума. За счёт этого она до 4 раз быстрее на видеокарте.
Чем DiffusionGemma отличается от обычной Gemma 4?
Скоростью и подходом: диффужнгемма быстрее в 3,5–4 раза, но качество ответов ниже. Обычную Gemma 4 Google советует там, где важно качество, а DiffusionGemma — для быстрых интерактивных задач и вставки текста.
Где скачать DiffusionGemma и сколько стоит?
Веса бесплатны и лежат на Hugging Face под лицензией Apache 2.0 (модель
). Платить не нужно, но из России для скачивания может понадобиться VPN.
Какая видеокарта нужна для DiffusionGemma?
В квантованном виде модель помещается в ~18 ГБ видеопамяти — то есть нужна топовая NVIDIA вроде RTX 4090 или 5090. Без своей видеокарты можно запустить в облаке через Model Garden или NVIDIA NIM.
Можно ли использовать DiffusionGemma в коммерческих проектах?
Да. Лицензия Apache 2.0 разрешает коммерческое использование, что для открытой модели большой плюс.
DiffusionGemma лучше ChatGPT?
Нет, это не конкурент ChatGPT по качеству. Это экспериментальный инструмент про скорость и локальный запуск. Для обычных вопросов качество ответов у неё ниже.
Также будет полезно
Российские нейросети, которые работают без VPN
Gemini vs ChatGPT vs Claude vs DeepSeek: что выбрать?
Промпты для DeepSeek — готовые шаблоны, которые работают
Источники:
Блог Google «The Keyword» — официальный анонс DiffusionGemma (